Implementing malloc & co.
A peak under the hood of dynamic memory management in C

For any programmer, there is some pride to be taken when memory management is done “manually” in an efficient, error-free way.
Nowadays, most modern programming languages use an automatic form of memory management called garbage collection. But there are still popular languages where one has to make sure memory is freed at the right time — that is as soon as possible after it is no longer needed, but not before that. C and C++ are two well-known examples of such languages.
Using malloc (for “memory allocator”) and free at the right time, a C programmer will already be doing a lot more in terms of manual memory management than if he were to use Java, for instance.
But taking things further, what do malloc and free (and others) do exactly under the hood? In what way and how often do they interact with the operating system (OS)? How should they be implemented in order to minimize overhead and maximize efficiency?
I decided to answer these questions by coding my own implementation of the C family of functions in charge of dynamic memory management, as part of my journey with the Qwasar Silicon Valley learning community.
In this post, I invite you to follow me through the various implementation decisions I had to take during this endeavour. Starting with an overview of the problem at hand, we will delve into some of the details of the solution. We will then take a high-level look at the implementation, and finally we will see how we were able to test it by running Firefox with it!
If you would like to follow along with the source code, it can be found on Github.
What is dynamic memory management?
Let us first take a step back and get a good grasp of the problem by properly establishing what is dynamic memory management.
In C, memory allocation can be divided into three categories: static, automatic and dynamic.
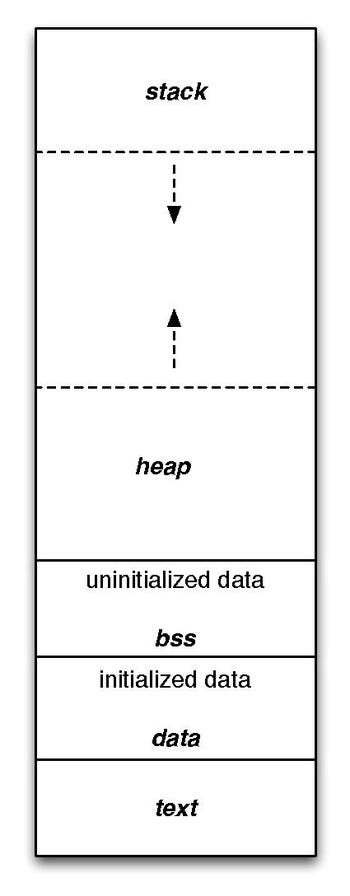
Static variables refer to those variables that are implemented at the start of the process and are only destroyed when the process returns to the OS. They are stored in the RAM, in a section called the data segment.
Automatic variables are also called local variables. Local data, function parameters, and return addresses are all implemented as automatic variables, which are also stored in the RAM, in a section called the stack (one stack per thread). The stack is implemented with an actual stack data structure. As function A calls function B which calls function C, automatic variables are simply added on the top of the stack: first are added the variables for A, then the ones for B and for C. When function C returns, the stack pointer simply goes back to point to the local variables of B, thereby making the local variables of C fall out of scope and effectively freeing them.
The stack being very simple and fast, the allocation of automatic variables is extremely efficient. However, those variables suffer from significant limitations which makes them unsuitable in many instances. First, an automatic variable can only be allocated if you know how much storage you need before compile time. Also, the storage needed cannot be very large, since the stack is relatively small (8 MB on my machine).
This is where dynamic allocation comes into play. You should indeed use it whenever you don’t know how much memory you will need at runtime or if you need large amounts of memory. Memory that is dynamically allocated is taken from a section of the RAM called the heap (one heap per process). Such memory is not freed when the variable that points to it falls out of scope. Instead, the programmer (or a garbage collector) has to free it. In C, this dynamic memory allocation is done by a function called malloc.
The most naive implementation of malloc would be to make it request memory to the OS each time it is called. That would work, but it would also be extremely inefficient, since calls to the OS incur a significant overhead. Instead, what malloc and other related functions do is they initially request from the OS a large chunk of memory, and subsequently properly manage that chunk. When the program calls malloc(n), requesting n bytes of memory, the function will first look whether it can accommodate the request with a block of memory that it already has under its management. Only if it cannot do so will it call the OS to request more memory from it.
Also, when the program calls free to free memory that is no longer needed, the function has to mark that memory as unused in some way, making it available to malloc when it will look for memory to allocate.
Putting all the aforementioned together, a proper dynamic memory management module has to perform the following tasks:
Find memory to accommodate requests, first by searching through memory already under management, then by requesting more memory from the OS if needed.
Free memory by marking it as unallocated.
For memory under management by the module, have a way to record what is allocated and what is not.
Do all of that in a way that is efficient and tries to avoid fragmentation.
The C family of functions in charge of dynamic memory management
Here are the functions that I implemented, along with their specifications:
malloc
Themalloc(size)function call allocatessizebytes and returns a pointer to the allocated memory.calloc
Thecalloc(nmemb, size)function call allocates memory for an array ofnmembelements ofsizebytes each and returns a pointer to the allocated memory.realloc
Therealloc(ptr, size)function call changes the size of the memory block pointed to byptrtosizebytes. The contents will be unchanged in the range from the start of the region up to the minimum of the old and new sizes.free
Thefree(ptr)function call frees the memory space pointed to byptr, which must have been returned by a previous call tomalloc,callocorrealloc.
My implementation: Basic ideas
Here are the ideas that provide the foundation for my implementation of the memory management module:
Memory blocks carry metadata in a header and a footer data structures (see Memory blocks: Their structure below).
When a block is freed, it is stored in a specific bucket (a circular doubly-linked list of blocks) from an array of buckets (see Buckets of free memory blocks below). The index of the specific bucket is a function of the size of the block to be stored.
This greatly facilitates our task when looking for memory to allocate: we can start our search with the bucket storing blocks of the desired size, and if needed, move to the next bucket until a suitable free block is found.
The first 128 buckets store only blocks of one particular size. The following buckets store a range of sizes. In the latter ones, blocks are inserted in the following way:
Blocks are kept in ascending size order. There is a bit of overhead incurred to insert the blocks in the right spot, but that extra work allows us to perform a best-fit search. In other words, when allocating a free memory block from the blocks under management, we can always be sure that the block provided by our search is the smallest one that can accommodate the requested size. According to an article by Doug Lea (the author of a famous malloc implementation), it was shown that best-fit schemes tended to produce the least fragmentation compared to other approaches.
Size ties are broken with an oldest-first rule, such that the storage of blocks of the same size will follow a first-in, first-out scheme.
When a block is freed, see if the previous block in memory is also free. If it is, coalesce them and store the resulting coalesced block instead of two smaller blocks. Do the same with the block following the block to be freed.
While this does not completely eliminates any fragmentation potential, it also helps a lot.
Memory blocks: Their structure
We define a header_t type to represent a memory block header type in the following way:

Note that size:48 means that the size field of the struct is only 48 bits long. We are trying to be space-efficient here. Logically, on the common x86-64 architecture, we would expect the virtual address space to be 64-bit long, but in reality only the least significant 48 bits are used. Practically speaking, that means that it is impossible, even theoretically, to allocate a memory block of more than 2^48 bytes (256 TB). This is why we only ever need 48 bits to store the block size.
So this leaves us with 16 bits left from our uint64_t field used in the beginning of the struct. From that we use one bit to store the free flag.
And we have 15 bits left to store the mapping field. This requires some explanation. Whenever malloc is called and it cannot find a suitable block from the ones already in management, a call is made to mmap to get a new memory mapping for the process in the virtual address space. The bounds of those mappings are stored in the mappings static 2-D array. For each mapping i (0 <= i < 2^15), mappings[i][0] and mappings[i][1] contain the lower (included) and upper (excluded) bounds, respectively, of the memory mapping. Note that consecutive mappings are merged into a single one.

This tracking of the mappings is actually useful when freeing a memory block, to know whether we should attempt to coalesce the block to be freed with the previous and next blocks in memory. Here is the relevant code from my free function, with variable block referencing the block to be freed:

Going back to the header_t struct, prev and next are pointers to the next and previous blocks in the bucket (not in memory) when self is free and stored in a bucket. Note that these fields are only relevant when the block is free. Hence, their content can be overwritten by the client when the block is in use. In other words, they are not part of the metadata of the memory block when it is in use.
We also define a single-member footer_t data structure, like so:

The purpose of this structure is to allow any block in memory to access the size of its previous block. Knowing its size, we can travel back to the header to know whether that previous block is free. If it is, we can coalesce both blocks.

Buckets of free memory blocks
As mentioned earlier, buckets are an array of circular doubly-linked lists of free blocks (each of those lists being, individually, a bucket).

In other words, memory blocks available to the client are stored in buckets, and each of them is associated with a certain size range. Here is the mapping between bucket index and block size:
0: 0
1: 8
2: 16
3: 24
4: 32
5: 40
... ...
n (n < 128): 8*n
... ...
127: 1016
128: {8*k : 2^7 <= k < 2^8} (i.e. {1024, 1032, 1040, ..., 2032, 2040})
129: {8*k : 2^8 <= k < 2^9}
130: {8*k : 2^9 <= k < 2^10}
... ...
n (128 <= n < 166): {8*k : 2^(n - 121) <= k < 2^(n - 120)}
... ...
165: {8*k : 2^44 <= k < 2^45}Here is a possible state for buckets[130] (storing blocks with sizes ranging from 4096 to 8184) at runtime.

Whenever one needs to get a free block from the buckets, or store a block to be freed in the buckets, the index of the relevant bucket is easily computed from the block size.

That code is to be read in conjunction with the index-to-size mapping set out above.
A high-level view of my implementation
Given all the aforementioned details, we are now ready to take a look at the implementation from a high-level viewpoint.
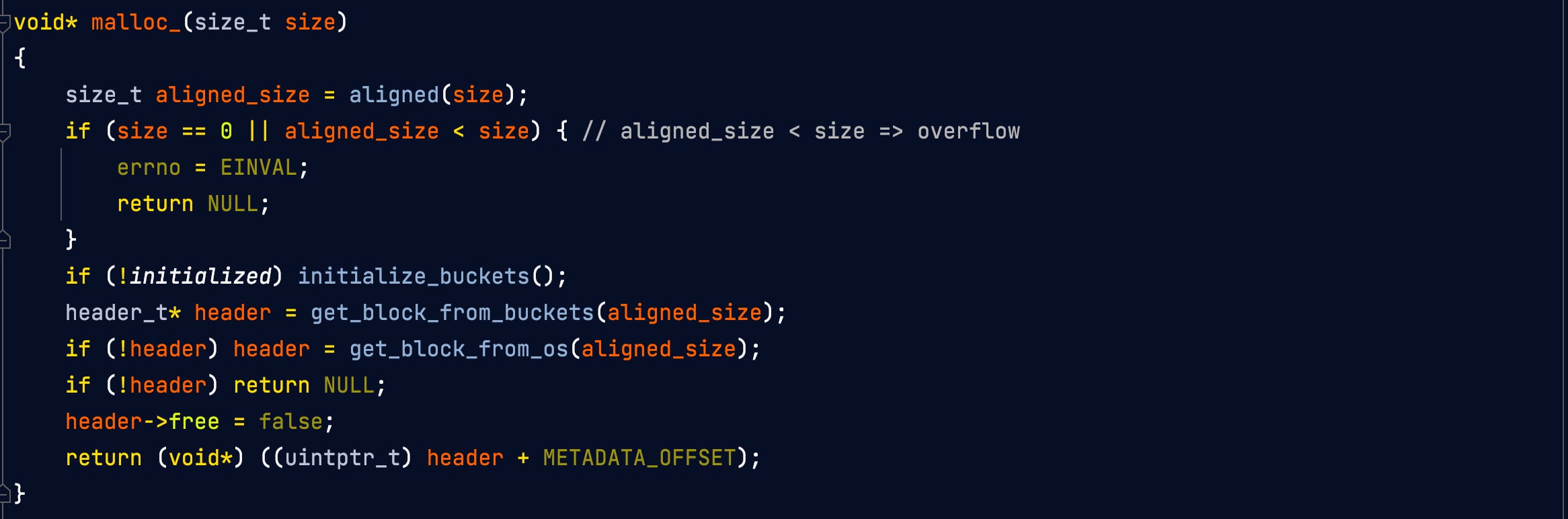



When two free blocks need to be coalesced to form a larger one, the logic is as simple as this:

A simple benchmark
As a first step, we can run a very basic benchmark.
I was relieved to see that my implementation seemed to run correctly, even outperforming the built-in functions on my machine. However, I know that doesn’t mean much, as there are many important housekeeping tasks that my code does not perform. Also, there are plenty of circumstances where my implementation would perform comparatively worse.
So let’s move on to the most interesting part: the Firefox test!
A real-life test: Running Firefox with my own malloc library
This test is going to be much more telling, yet it relies on a very simple idea: run Firefox, but have it use my own malloc library instead of the built-in one.
For that we have to use what is called the LD_PRELOAD trick. LD_PRELOAD is an environment variable that can be set to the path to a certain shared library when running a program on the command line, thus asking the dynamic linker to bind symbols provided by that shared library before other libraries.
In this case, the shared library will be comprised of our four custom memory management functions (malloc, calloc, realloc and free), and the program run will be Firefox. We will ask the dynamic linker to bind malloc, calloc, realloc and free to our custom library, not to the system’s C library.
Preliminary steps
Because I initially wanted to test my own malloc against the built-in one, my own free against the built-in one, etc. (see A simple benchmark above), I used an underscore suffix after the function names (malloc_, calloc_, realloc_ and free_) as to avoid name conflicts. So a preliminary step is to simply rename these functions using the original names, sans the underscore.
On Linux systems
On Linux systems, the process is trivial. First, create the shared library. From the root directory of my project, run:
$ gcc -shared -o malloc.so -fPIC src/malloc.cNote that src/malloc.c contains all four desired functions. Next, run Firefox with LD_PRELOAD set to the path of that newly created library:
$ LD_PRELOAD=$PWD/malloc.so firefoxNote that we provide an absolute path to the malloc.so library, in case the executable’s working directory differs from the current directory.
And that’s how I would run Firefox with my own memory management library on a Linux system.
On macOS
Being on macOS, however, I have some work left to do in order to perform the test. While it is true that a similar trick can be pulled off on macOS, the process involves much more code changes.
Fortunately, I found a fairly simple way to run Firefox on a lightweight, GUI-less Ubuntu virtual machine while displaying it on my Mac!
First, let’s prepare our host system to receive the display from the guest VM. In order to do that, follow the steps set out on this page under Set up and configure XQuartz on Mac.
After XQuartz is configured, launch it.
Then, install multipass:
> brew install --cask multipassSo after multipass is installed, execute that command:
> multipass shellWritten like that without any argument, the command opens the shell prompt of the default instance called primary. Upon logging into the primary instance, the VM’s private IP address is displayed: 192.168.64.3.
Now, on the host system, execute:
> xhost +192.168.64.3This will instruct the XQuartz display server to accept connections from the primary instance.
In order to run Firefox, we need to install it in the VM:
ubuntu@primary:~$ sudo snap install firefoxAt this point, we can already run Firefox from the VM and make it display on our host system through XQuartz (albeit not using our own memory management library yet). The DISPLAY environment variable contains my host’s private IP:
ubuntu@primary:~$ DISPLAY=192.168.1.4:0 firefoxBack to our host system (macOS), we mount our home directory into the VM (the multipass instance called primary):
> multipass mount ~ primary:~/HomeThe next step is to install the gcc compiler in the VM:
> sudo apt install gccNow before I attempt to run Firefox properly with my library, I will use my library to make Firefox crash. That way, I know that the memory management function calls from Firefox are indeed handled by my own code. In order to do that, I simply add this line at the top of my malloc function:
int* x = NULL; x[0] = 0;This should induce a segmentation fault as soon as Firefox calls malloc. Let’s now build the shared library from the faulty code. From the project’s root directory:
ubuntu@primary:~/Home/my_malloc$ gcc -shared -o malloc.so -fPIC src/malloc.cAnd then:
ubuntu@primary:~/Home/my_malloc$ LD_PRELOAD=$PWD/malloc.so DISPLAY=192.168.1.4:0 firefoxAs expected, we get:
Segmentation fault (core dumped)This is great news! It is confirmation that our code was properly injected.
We now remove the line added previously to induce the segmentation fault, and then rebuild the malloc.so shared library. We subsequently rerun the previous Firefox command:
ubuntu@primary:~/Home/my_malloc$ LD_PRELOAD=$PWD/malloc.so DISPLAY=192.168.1.4:0 firefoxAnd voilà! Mission accomplished: Firefox runs with our custom memory management library.
Potential downsides and areas of improvement
The main “danger” that I see with this implementation is the lack of error detection. More precisely, no checks are made to ensure that header and footer metadata were unaltered during client use. Corruption of this metadata will break the program. A way of dealing with this would be to include some sort of checksum verification.
Also, blocks under management by this implementation have a minimum size of 32 bytes. In a program where the client only ever needs very small blocks, i.e., blocks of 16 bytes (to store two pointers on a system with 8-byte pointers), memory allocation will suffer a 100% overhead.
Final words
Thank you for taking the time to read this post. If you have any questions, or would like to point out an error or make a suggestion, please feel free to write a comment.